- Créer un sous-dossier «TP12» dans le dossier «TP_informatique_commune» de votre repertoire personnel
- Si on vous demande d'écrire un script python à la question 3\c) de l'activité 2 du TP 7 vous enregistrez ce script dans un fichier nommé «tp07_act02_q03c.py». Remarquez que l'on utilisera toujours deux chiffres décimaux pour représenter les entiers et que l'on va toujours du général vers le particulier car ainsi l'ordre alphabétique correspond à l'ordre tri chronologique.
- On rendra son code modulaire en utilisant systématiquement des fonctions
- On testera toutes ses fonctions
1. Un algorithme naïf
Un premier algorithme naif (juste mais peu efficace) pour calculer les distances minimales en partant d'un sommet
startfixé est- de partir d'une liste
dist_listde distances toutes infines sauf celle correspondant au sommetstartqui vaut0; - puis dans une boucle on teste "tous les potentiels raccourcis"
et si on trouve un vrai raccourci alors on modifie
dist_listen conséquence. Plus précisément la boucle- est effectuée tant que la liste
dist_listest modifiée; - et si on trouve deux sommets
i_tmpeti2tels quedist_list[i_tmp]+A[i_tmp][i2]<dist_list[i2](on a trouvé un raccourci en passant pari_tmp) alors on modifiedist_list[j]en conséquence.
- est effectuée tant que la liste
Enfin, comme on veut pouvoir récupérer un chemin de longueur minimal partant de
startet arrivant à un autre sommet quelconque on maintient un dictinnaire d'association sommet_somemt appeléparent_dicttel que pour tout sommetsl'expressionsparent_dict[s]renvoie le sommet précédentssur un plus court chemin allant destartàs.Compléter la fonction suivante pour qu'elle implémente cet algorithme où le graphe est donné sous la forme d'un dictionnaire de dictionnaires d'associations successeur/longueur.
def algo_naif_dist_a_sommet_fixe_succdict(G_succ, i): n = len(G_succ) assert i in G_succ dist_dict = {s: ?? for s in G_succ} parent_dict = {s: ?? for s in G_succ} dist_dict[i] = ?? something_changed = ?? while something_changed: something_changed = ?? for s_tmp in G_succ: for s2 in G_succ[s_tmp]: other_dist = dist_dict[s_tmp]+G_succ[??][s2] if other_dist ?? dist_dict[s2]: dist_dict[s2] = ?? parent_dict[s2] = ?? something_changed = ?? return parent_dict, dist_dict def teste_algo_naif_dist_a_sommet_fixe_succdict(): G = { "A": {"B": 9, "C": 1}, "B": {"A": 1, "C": 1}, "C": {"A": 1, "B": 1} } par_d, dist_d = algo_naif_dist_a_sommet_fixe_succdict(G, "A") assert dist_d == {"A": ??, "B": ??, "C": ??} assert par_d == {"A": ??, "B": ??, "C": ??} G["A"]["B"] = 1 par_d, dist_d = algo_naif_dist_a_sommet_fixe_succdict(G, "A") assert dist_d == {"A": ??, "B": ??, "C": ??} assert par_d == {"A": ??, "B": ??, "C": ??} teste_algo_naif_dist_a_sommet_fixe_succdict()(seulement si vous êtes en avance) Compléter la fonction
algo_naif_dist_a_sommet_fixe_matadjci-dessous pour qu'elle implémente le même algorithme quealgo_naif_dist_a_sommet_fixe_succdictmais où le graphe est donné sous la forme d'une matrice d'adjacence.def algo_naif_dist_a_sommet_fixe_matadj(A, i): n, p = A.shape assert n==p assert 0 <= i and i < n dist_list = [??] * n dist_list[i] = ?? something_changed = ?? while something_changed: something_changed = ?? for i2 in range(??): for i_tmp in range(??): other_dist = dist_list[i_tmp]+A[i_tmp][i2] if ?? < ??: dist_list[i2] = other_dist something_changed = True return ?? def teste_algo_naif_dist_a_sommet_fixe_matadj(): A = np.array([[0, 9, 1], [1, 0, 1], [1, 1, 0]]) d = algo_naif_dist_a_sommet_fixe_matadj(A, 0) assert d == ?? A = np.array([[0, 2, np.inf, np.inf], [3, 0, np.inf, np.inf], [np.inf, np.inf, 0, 4], [np.inf, np.inf, 5, 0]]) d = algo_naif_dist_a_sommet_fixe_matadj(A, 0) assert d == ?? A[0,2] = 121 d = algo_naif_dist_a_sommet_fixe_matadj(A, 0) assert d == ?? teste_algo_naif_dist_a_sommet_fixe_matadj()Vérifier alors que le programme suivant affiche tour à tour les image ci-dessous
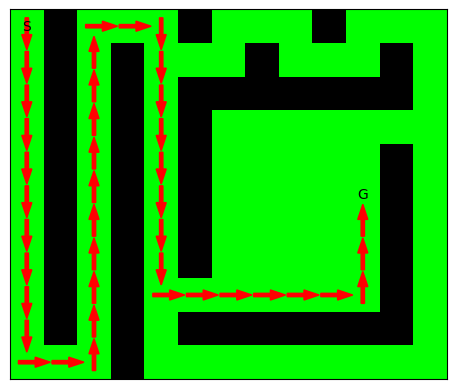
maze = np.array([ [0, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0], [0, 1, 0, 1, 0, 0, 0, 1, 0, 0, 0, 1, 0], [0, 1, 0, 1, 0, 1, 1, 1, 1, 1, 1, 1, 0], [0, 1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0], [0, 1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 0], [0, 1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 0], [0, 1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 0], [0, 1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 0], [0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0], [0, 1, 0, 1, 0, 1, 1, 1, 1, 1, 1, 1, 0], [0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0], ]) G_succ = maze_to_succdict(maze) start = (0, 0) par_d, dist_d = algo_naif_dist_a_sommet_fixe_succdict(G_succ, start) # --- goal = (3, 10) path = create_path_using_parent_dict(par_d, goal) plot_maze_and_paths(maze, [path]) plt.show() # --- goal = (5, 10) path = create_path_using_parent_dict(par_d, goal) plot_maze_and_paths(maze, [path]) plt.show()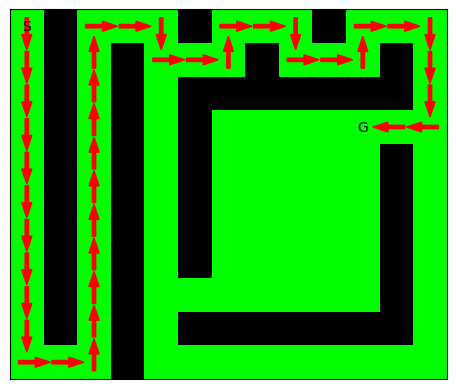
- de partir d'une liste
2. Files de priorité
- un type peut être considéré comme une file de priorité s'il fournit
- une fonction ou une méthode qui permet d'ajouter un élément avec
un priorité donnée (priorité qui doit être de type numérique,
floatouint) - une fonction ou une méthode qui permet de récuperer l'élément de plus petite priorité (parfois c'est celui de plus grande priorité qui est renvoyé mais quitte à changer toutes les priorité en leuurs opposé cela ne pose pas de problème car l'opposé du plus grand élément est le plus petit des opposés)
- une fonction ou une méthode qui permet d'ajouter un élément avec
un priorité donnée (priorité qui doit être de type numérique,
Le module built-in heapq fourni des fonctions qui permettent
d'utiliser le type list comme une file de priorité. Comme ce module
n'est pas concepteur du type list 'qui est built-in) il ne peut pas
créer de méthode du type list donc ce module fournit
(malheureusement) des fonctions alors que des méthodes seraient plus
naturelle…
Remarques:
- pour des raisons de performance le module
heapqne maintient pas la liste triée dans l'ordre croissant des priorités mais procède de façon plus subtile (ce qui permet de passer d'une complexe linéaire en la longueur de la file à une complexité logarithmique soit un gros gain) Ainsi il ne faut pas accéder aux éléments d'une file de priorité à l'aide des méthode du type liste mais utiliser uniquement les fonctions fournies par le module
heapqVérifier que le code ci-dessous affiche bien la sortie donnée en-dessous
import heapq pq = [] # pq pour 'priority queue': file de priorité heapq.heappush(pq, (10, "a")) heapq.heappush(pq, (11, "b")) heapq.heappush(pq, (12, "c")) heapq.heappush(pq, (9, "d")) print("Longueur:", len(pq)) prio, elmt = heapq.heappop(pq) print("prio, elmt:", prio, elmt) print("Longueur:", len(pq)) prio, elmt = heapq.heappop(pq) print("prio, elmt:", prio, elmt) print("Encore un petit 'heappush'...") heapq.heappush(pq, (3, "e")) print("Longueur:", len(pq)) prio, elmt = heapq.heappop(pq) print("prio, elmt:", prio, elmt) print("Longueur:", len(pq)) prio, elmt = heapq.heappop(pq) print("prio, elmt:", prio, elmt) print("Longueur:", len(pq)) prio, elmt = heapq.heappop(pq) print("prio, elmt:", prio, elmt) print("Longueur:", len(pq))Longueur: 4 prio, elmt: 9 d Longueur: 3 prio, elmt: 10 a Encore un petit 'heappush'... Longueur: 3 prio, elmt: 3 e Longueur: 2 prio, elmt: 11 b Longueur: 1 prio, elmt: 12 c Longueur: 0
Compléter la fonction de test suivante pour que tous les tests passent.
import heapq def teste_module_heapq(): pq = [] # pq pour 'priority queue': file de priorité for prio, elmt in [(6,"a"), (4,"b"), (5,"c"), (7,"d")]: heapq.heappush(pq, (prio, elmt)) prio, elmt = heapq.heappop(pq) assert prio == ?? and elmt == ?? prio, elmt = heapq.heappop(pq) assert prio == ?? and elmt == ?? heapq.heappush(pq, (8, "e")) heapq.heappush(pq, (0, "f")) heapq.heappush(pq, (9, "g")) prio, elmt = heapq.heappop(pq) assert prio == ?? and elmt == ?? teste_module_heapq()
3. Algorithme de Dijkstra
Compléter le code suivant pour que
- la fonction
teste_dijkstra_succdictimplémente l'algorithme de Dijkstra en retournant dans l'ordre- un dictionnaire de prédecesseurs permettant de récupérer le
chemin le plus court arrivant à un sommet donné en partout du
sommet source
start; - et un dictionnaire de distance donnant la distance entre un
sommet donné et le sommet source
start.
- un dictionnaire de prédecesseurs permettant de récupérer le
chemin le plus court arrivant à un sommet donné en partout du
sommet source
On utilisera la structure de file de priorité implémentée par-dessus le type
listpar le module heapq.import heapq def dijkstra_succdict(G_succdict, start): n = len(G_succdict) assert start in G_succdict node_dist_dict = {s: ?? for s in G_succdict} node_dist_dict[start] = ?? was_visited_list = {s: ?? for s in G_succdict} was_visited_list[start] = ?? node_to_par_in_minmath = {s: ?? for s in G_succdict} pq = [] # 'priority queue': file de priorité priority, node = 0, start heapq.heappush(pq, (priority, node)) while len(pq) > 0: prio, node = heapq.heappop(pq) # rappel: dans l'algorithme de Dijkstra on récupère à chaque # étape le sommet `node` dont la distance estimée (un majorant # de la distance réelle) au sommet source `start` n'est pas # encore connue ("sommet jamais souligné") mais est minimale # parmi ceux-ci. Pour ce sommet la distance estimée est en # fait bonne et ne sera plus jamais changée ("sommet # souligné") et on regarde si pour les sommets S de distance # non encore connue la concaténation du chemin minimal start-S # puis de l'arc S-node (s'il existe, si ce n'est pas le cas sa # distance est comptée infinie) donne une distance plus petite # que la distance de S estimée jusqu'alors. # # sommet souligné = distance connue = was_visited_list[node] == True was_visited_list[node] = ?? for adj_node in G_succdict[node]: if was_visited_list[adj_node]: ?? maybe_smaller_dist = node_dist_dict[node] + G_succdict[??][??] if maybe_smaller_dist ?? node_dist_dict[adj_node] : node_to_par_in_minmath[adj_node] = ?? node_dist_dict[adj_node] = ??_dist heapq.heappush(pq, (maybe_smaller_dist, adj_node)) # rmq: il est possible que le somme adj_node soit # présent plusieurs fois dans la file de priorité pq # avec différentes priorité mais seule son occurence # de priorité minimale sera prise en compte et on # pourrait enlever toutes les autres occurences # (compromis temps/mémoire: cela prend du temps de # calcul mais fait gagner un peu de mémoire càd on # perd en complexité temporelle mais on gagne en # complexité spatiale) return node_to_par_in_minmath, node_dist_dict def teste_dijkstra_succdict(): G_succdict = { "A": {"B": 1,"C": 3,"D": 4}, "B": {"A": 1,"C": 1,"D": 4}, "C": {"A": 1,"B": 1,"D": 1}, "D": {"A": 1,"B": 1,"C": 1}, } par_dict, dist = dijkstra_succdict(G_succdict, "A") assert par_dict == {"A": None, "B": "A", "C": "B", "D": "C"} assert dist["A"] == 0 assert dist["D"] == 3 G_succdict = { "A": {"A": 0,"B": 2}, "B": {"A": 3,"B": 0}, "C": {"C": 0, "D": 4}, "D": {"C": 5, "D": 0}, } par_dict, dist = dijkstra_succdict(G_succdict, "A") assert par_dict == {'A': None, 'B': 'A', 'C': None, 'D': None} assert {'A': 0, 'B': 2, 'C': np.inf, 'D': np.inf} teste_dijkstra_succdict()- la fonction
Vérifier que le code ci-dessous vous affiche alors les deux images qui suivent
import matplotlib.pyplot as plt from matplotlib.colors import ListedColormap def maze_to_succdict(maze): n, p = maze.shape succ_dict = {} for i in range(n): for j in range(p): s = (i,j) if maze[i, j] != 0: continue succ_s_dict = {} for di, dj in [(1,0), (0,1), (-1,0), (0,-1)]: i_adj, j_adj = i+di, j+dj i_adj_asmissible = i_adj >= 0 and i_adj < n j_adj_asmissible = j_adj >= 0 and j_adj < p if not i_adj_asmissible or not j_adj_asmissible or maze[i_adj, j_adj] != 0: continue succ_s_dict[(i_adj, j_adj)] = 1 succ_dict[s] = succ_s_dict return succ_dict def teste_maze_to_succdict(): maze = np.array([ [0, 0, 0], [1, 1, 1], [0, 0, 1], ]) res = { (0, 0): {(0, 1): 1}, (0, 1): {(0, 0): 1, (0, 2): 1}, (0, 2): {(0, 1): 1}, (2, 0): {(2, 1): 1}, (2, 1): {(2, 0): 1}, } assert maze_to_succdict(maze) == res teste_maze_to_succdict() def create_path_using_parent_dict(parent_dict, goal): path, s = [], goal while s is not None: path.append(s) s = parent_dict[s] assert s not in path # no loop return list(reversed(path)) def teste_create_path_using_parent_dict(): # A -> C -> B -> E ; D parent_dict = { "A": None, "B": "C", "C": "A", "D": None, "E": "B" } goal = "E" path = create_path_using_parent_dict(parent_dict, goal) assert path == ["A", "C", "B", "E"] teste_create_path_using_parent_dict() def plot_maze_and_paths(maze, path_list, ax = None): ax = plt.gca() if ax is None else ax colors = [[0,1,0], [0,0,0], [0,0,1]] maze = maze.copy() # prevents side-effects for path in path_list: for s in path: i, j = s assert maze[i, j] == 0 maze[i, j] = 2 ax.set_xticks([], minor=False) ax.set_yticks([], minor=False) ax.set_aspect('equal') #set the x and y axes to the same scale ax.invert_yaxis() #invert the y-axis so the first row of data is at the top ax.pcolormesh(maze, vmin=0, vmax=2, cmap=ListedColormap(colors)) maze = np.array([ [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0], [0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], ]) G_succ = maze_to_succdict(maze) start = (4, 5) # --- goal = (5, 12) par_dict, dist = dijkstra_succdict_un_sommet(G_succ, start, goal) path = create_path_using_parent_dict(par_dict, goal) plot_maze_and_paths(maze, [path]) plt.show() # --- goal = (10, 12) par_dict, dist = dijkstra_succdict_un_sommet(G_succ, start, goal) path = create_path_using_parent_dict(par_dict, goal) plot_maze_and_paths(maze, [path]) plt.show()--------------------------------------------------------------------------- NameError Traceback (most recent call last) Cell In[591], line 96 94 # --- 95 goal = (5, 12) ---> 96 par_dict, dist = dijkstra_succdict_un_sommet(G_succ, start, goal) 97 path = create_path_using_parent_dict(par_dict, goal) 98 plot_maze_and_paths(maze, [path]) NameError: name 'dijkstra_succdict_un_sommet' is not defined
4. Algorithme A* (A star)
- Pour calculer la longueur du plus court chemin d'un sommet
"A"à un sommet"B"l'algorithme de Djikstra calcule les distances à et en partant de"A"de tous (ou au moins beaucoups) de sommets alors que parfois on se doute qu'il est en général plus malin de choisir une direction plutôt qu'une autre. - Ceci est très lourd en temps et en mémoire.
- Ici on suppose donnée une heuristique
h(facile à calculer) telle queh<=d(sinon l'algorithme ne fonctionne pas). Pour le cas oùhest constante égale à zéro (cette heuristique ne fournit donc aucune information) l'algorithme A* dégénère en l'algorithme de Dijkstra. - dans l'espace ou dans le plan avec des obstacles on prend souvent pour heuristique la distance à vol d'oiseau (qui minore bien la distance recherchée puisqu'elle ignore les obstacles) dont la formule en coordonnées est très rapide à évaluer!
Vérifier que le code ci-dessous fonctionne
import math def null_heuristic(P, Q): return 0 def manhattan_heuristic(P, Q): return abs(P[0]-Q[0])+abs(P[1]-Q[1]) def as_the_crow_flies_heuristic(P, Q): return ((P[0]-Q[0])**2+(P[1]-Q[1])**2)**(1/2) def favor_good_diags_heuristic(P, Q): return max(abs(P[0]-Q[0]),abs(P[1]-Q[1])) def favor_good_horiz_heuristic(P, Q): return abs(P[1]-Q[1]) def favor_good_vert_heuristic(P, Q): return abs(P[0]-Q[0]) maze = np.array([ [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0], [0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0], [0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0], [0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0], [0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0], [0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0], [0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 0, 0, 0, 0, 0], [0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0], [0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0], [0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0], [0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0], [0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0], [0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 0, 1, 1, 1, 0, 0, 0, 0, 0], [0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0], [0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0], [0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0], [0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0], [0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0], [0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], ]) start, goal = (10, 10), (10, 24) data = [ { "maze": maze, "start": start, "goal": goal, "heuristic": null_heuristic, }, { "maze": maze, "start": start, "goal": goal, "heuristic": manhattan_heuristic, }, { "maze": maze, "start": start, "goal": goal, "heuristic": as_the_crow_flies_heuristic, }, { "maze": maze, "start": start, "goal": goal, "heuristic": favor_good_diags_heuristic, }, { "maze": maze, "start": start, "goal": goal, "heuristic": favor_good_horiz_heuristic, }, { "maze": maze, "start": start, "goal": goal, "heuristic": favor_good_vert_heuristic, }, ] data_len = len(data) n, p = 2, 3 fig, axs = plt.subplots(nrows=n, ncols=p, figsize=(15,15)) for i, d in enumerate(data): maze = d["maze"] heuristic = d["heuristic"] G_succ = maze_to_succdict(maze) par_dict, dist = astar_succdict(G_succ, start, goal, heuristic) path = create_path_using_parent_dict(par_dict, goal) n, p = i//3, i%3 ax = axs[i//3, i%3] plot_maze_and_paths(maze, [path], ax) ax.set_title(heuristic.__name__) plt.tight_layout() plt.show()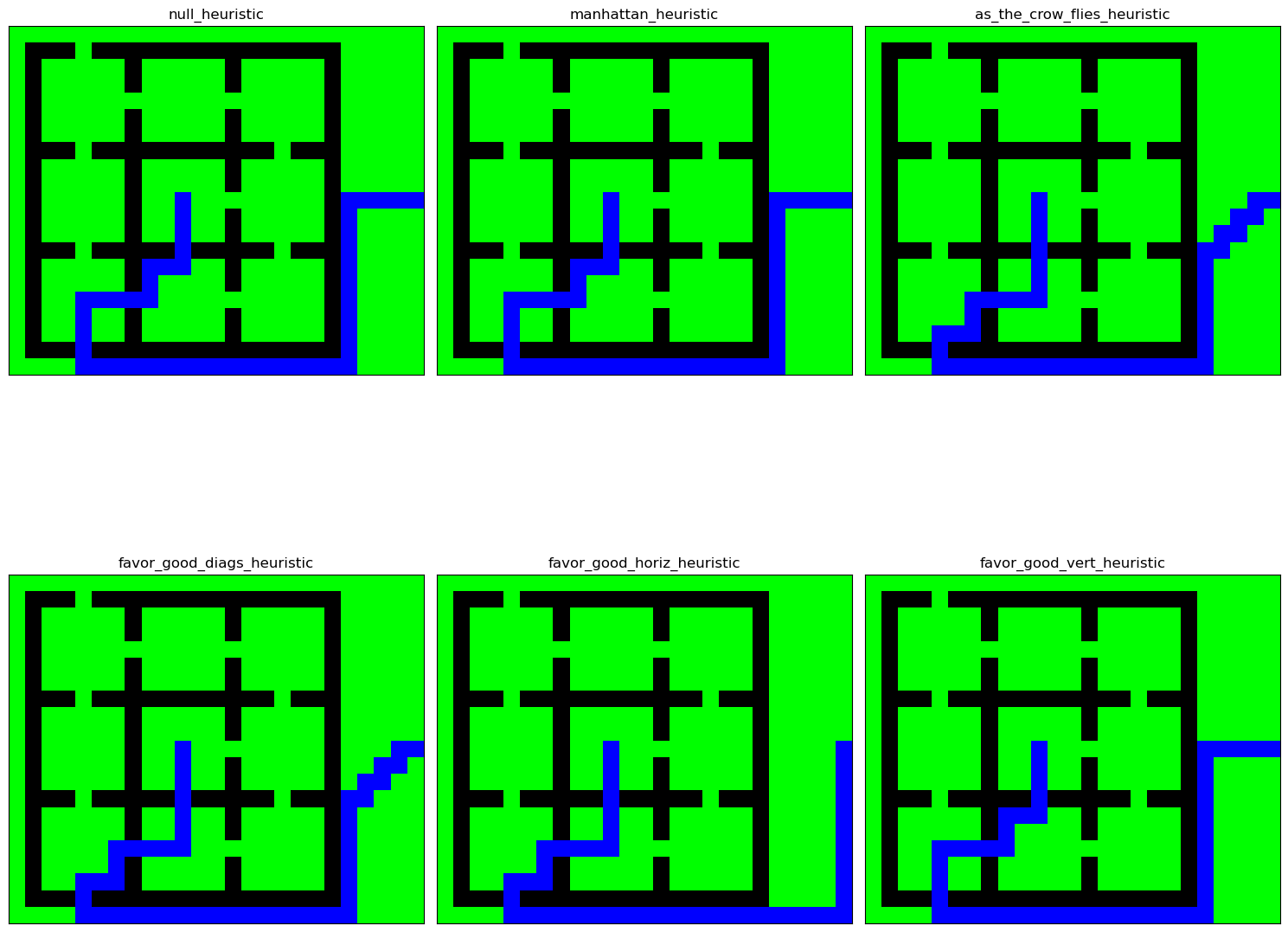
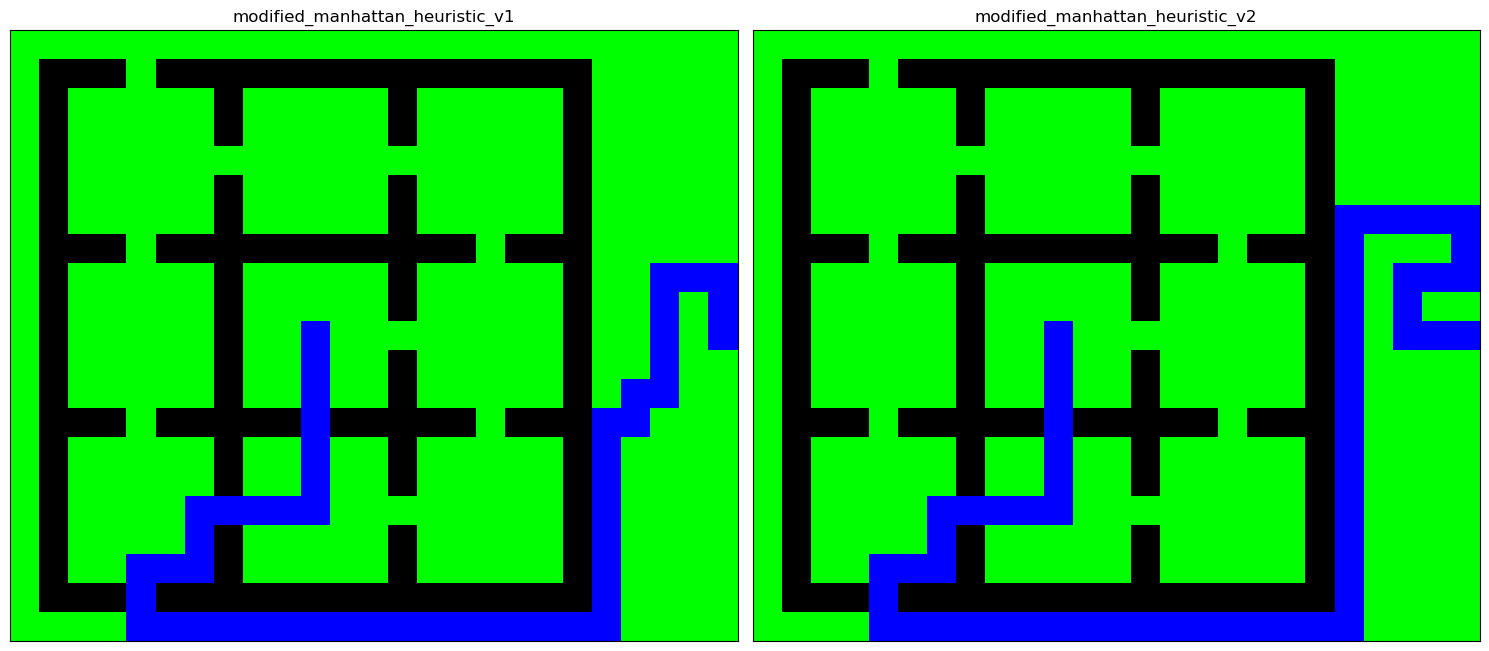
On propose deux (mauvaises) heuristiques obtenues en modifiant une bonne heuristique à l'arrivée. vérifier que vous obtenez les graphiques ci-dessous;
import math def modified_manhattan_heuristic_v1(P, Q): addtve_mask_near_goal = [ [-40,-40,-40, 99, 99], [-40, 99,-40, 99, 99], [-40, 99,-40, 99, 99], [-40, 99, 99, 99, 99], [-40, 99, 99, 99, 99], ] n = len(addtve_mask_near_goal) #5 rad = n // 2 #2 if abs(P[0]-Q[0]) > rad or abs(P[1]-Q[1]) > rad: return max(abs(P[0]-Q[0]),abs(P[1]-Q[1])) di, dj = P[0]-Q[0], P[1]-Q[1] add = addtve_mask_near_goal[di+rad][dj+rad] return add+max(abs(P[0]-Q[0]),abs(P[1]-Q[1])) def modified_manhattan_heuristic_v2(P, Q): addtve_mask_near_goal = [ [-10, -10, -10, -10, -10, 99, 99, 99, 99], [-10, 99, 99, 99, -10, 99, 99, 99, 99], [-10, 99, -10, -10, -10, 99, 99, 99, 99], [-10, 99, -10, 99, 99, 99, 99, 99, 99], [-10, 99, -10, -10, -10, 99, 99, 99, 99], [-10, 99, 99, 99, 99, 99, 99, 99, 99], [-10, 99, 99, 99, 99, 99, 99, 99, 99], [-10, 99, 99, 99, 99, 99, 99, 99, 99], [-10, 99, 99, 99, 99, 99, 99, 99, 99], ] n = len(addtve_mask_near_goal) #9 rad = n // 2 #4 if abs(P[0]-Q[0]) > rad or abs(P[1]-Q[1]) > rad: return max(abs(P[0]-Q[0]),abs(P[1]-Q[1])) di, dj = P[0]-Q[0], P[1]-Q[1] add = addtve_mask_near_goal[di+rad][dj+rad] return add+max(abs(P[0]-Q[0]),abs(P[1]-Q[1])) maze = np.array([ [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0], [0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0], [0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0], [0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0], [0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0], [0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0], [0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 1, 1, 1, 0, 0, 0, 0, 0], [0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0], [0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0], [0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0], [0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0], [0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0], [0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 0, 1, 1, 1, 1, 1, 0, 1, 1, 1, 0, 0, 0, 0, 0], [0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0], [0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0], [0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0], [0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0], [0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0], [0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], ]) start, goal = (10, 10), (10, 24) data = [ { "maze": maze, "start": start, "goal": goal, "heuristic": modified_manhattan_heuristic_v1, }, { "maze": maze, "start": start, "goal": goal, "heuristic": modified_manhattan_heuristic_v2, }, ] data_len = len(data) n, p = 1, 2 fig, axs = plt.subplots(nrows=n, ncols=p, figsize=(15,15)) for i, d in enumerate(data): maze = d["maze"] heuristic = d["heuristic"] G_succ = maze_to_succdict(maze) par_dict, dist = astar_succdict(G_succ, start, goal, heuristic) path = create_path_using_parent_dict(par_dict, goal) ax = axs[i] plot_maze_and_paths(maze, [path], ax) ax.set_title(heuristic.__name__) plt.tight_layout() plt.show()